A data analyst has recently joined a new team that uses Databricks SQL, but the analyst has never used Databricks before. The analyst wants to know where in Databricks SQL they can write and execute SQL queries.
On which of the following pages can the analyst write and execute SQL queries?
Correct Answer:
E
The SQL Editor page is where the analyst can write and execute SQL queries in Databricks SQL. The SQL Editor page has a query pane where the analyst can type or paste SQL statements, and a results pane where the analyst can view the query results in a table or a chart. The analyst can also browse data objects, edit multiple queries, execute a single query or multiple queries, terminate a query, save a query, download a query result, and more from the SQL Editor page. References: Create a query in SQL editor
A data analyst has been asked to count the number of customers in each region and has written the following query:
If there is a mistake in the query, which of the following describes the mistake?
Correct Answer:
B
In the provided SQL query, the data analyst is trying to count the number of customers in each region. However, they made a mistake by not including the ??GROUP BY?? clause to group the results by region. Without this clause, the query will not return counts for each distinct region but rather an error or incorrect result. References: The need for a GROUP BY clause in such queries can be understood from Databricks SQL documentation: Databricks SQL.
I also noticed that you uploaded an image with your question. The image shows a snippet of an SQL query written in plain text on a white background. The query is attempting to select regions and count customers from a ??customers?? table and order the results by region. There??s no visible syntax highlighting or any other color - it??s monochromatic. The query is the same as the one in your question. I??m not sure whyyou included the image, but maybe you wanted to show me the exact format of your query. If so, you can also use code blocks to display formatted content such as SQL queries. For example, you can write: SELECT region, count(*) AS number_of_customers
FROM customers ORDER BY region;
This way, you can avoid uploading images and make your questions more clear and concise. I hope this helps.
A data analyst has been asked to use the below tablesales_tableto get the percentage rank of products within region by the sales:
The result of the query should look like this:
Which of the following queries will accomplish this task?
A)
B)
C)
D)
Correct Answer:
B
The correct query to get the percentage rank of products within region by the sales is option B. This query uses the PERCENT_RANK() window function to calculate the relative rank of each product within each region based on the sales amount. The window function is partitioned by region and ordered by sales in descending order. The result is aliased as rank and displayed along with the region and product columns. The other options are incorrect because:
✑ A. Option A uses the RANK() window function instead of the PERCENT_RANK() function. The RANK() function returns the rank of each row within the partition, but not the percentage rank. Also, the query does not have a GROUP BY clause, which is required for aggregate functions like SUM().
✑ C. Option C uses the DENSE_RANK() window function instead of the PERCENT_RANK() function. The DENSE_RANK() function returns the rank of each row within the partition, but not the percentage rank. Also, the query does not have a GROUP BY clause, which is required for aggregate functions like SUM().
✑ D. Option D uses the ROW_NUMBER() window function instead of the PERCENT_RANK() function. The ROW_NUMBER() function returns the sequential number of each rowwithin the partition, but not the percentage rank. Also, the query does not have a GROUP BY clause, which is required for aggregate functions like SUM(). References:
✑ 1: PERCENT_RANK (Transact-SQL)
✑ 2: Window functions in Databricks SQL
✑ 3: Databricks Certified Data Analyst Associate Exam Guide
A data analyst is working with gold-layer tables to complete an ad-hoc project. A stakeholder has provided the analyst with an additional dataset that can be used to augment the gold-layer tables already in use.
Which of the following terms is used to describe this data augmentation?
Correct Answer:
E
Data enhancement is the process of adding or enriching data with additional information to improve its quality, accuracy, and usefulness. Data enhancement can be used to augment existing data sources with new data sources, such as external datasets, synthetic data, or machine learning models. Data enhancement can help data analysts to gain deeper insights, discover new patterns, and solve complex problems. Data enhancement is one of the applications of generative AI, which can leverage machine learning to generate synthetic data for better models or safer data sharing1.
In the context of the question, the data analyst is working with gold-layer tables, which are curated business-level tables that are typically organized in consumption-ready project- specific databases234. The gold-layer tables are the final layer of data transformations and data quality rules in the medallion lakehouse architecture, which is a data design pattern used to logically organize data in a lakehouse2. The stakeholder has provided the analyst with an additional dataset that can be used to augment the gold-layer tables already in use. This means that the analyst can use the additional dataset to enhance the existing gold- layer tables with more information, such as new features, attributes, or metrics. This data augmentation can help the analyst to complete the ad-hoc project more effectively and efficiently.
References:
✑ What is the medallion lakehouse architecture? - Databricks
✑ Data Warehousing Modeling Techniques and Their Implementation on the Databricks Lakehouse Platform | Databricks Blog
✑ What is the medallion lakehouse architecture? - Azure Databricks
✑ What is a Medallion Architecture? - Databricks
✑ Synthetic Data for Better Machine Learning | Databricks Blog
A data analyst runs the following command: SELECT age, country
FROM my_table
WHERE age >= 75 AND country = 'canada';
Which of the following tables represents the output of the above command?
A)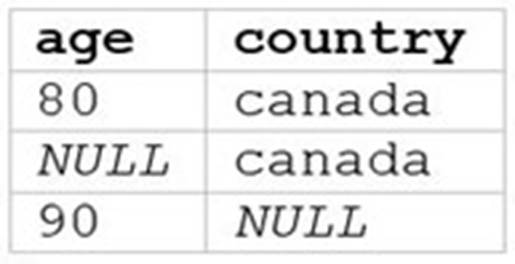
B)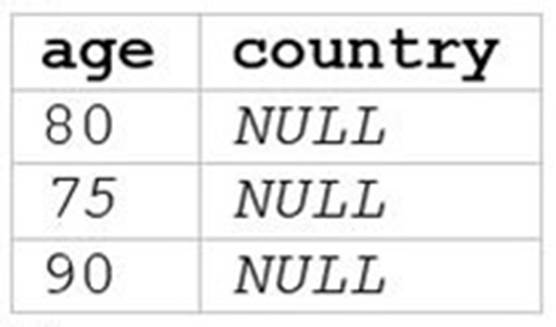
C)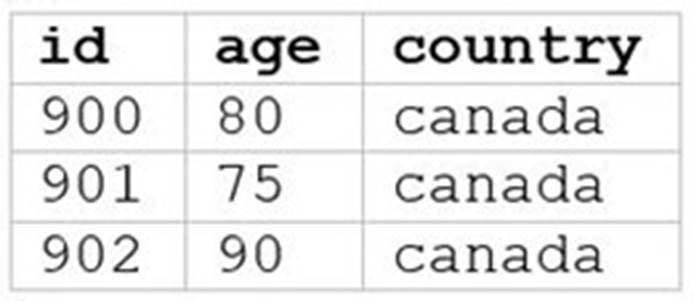
D)
E)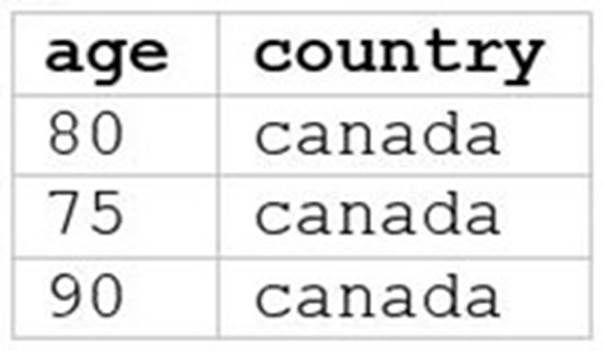
Correct Answer:
E
The SQL query provided is designed to filter out records from ??my_table?? where the age is 75 or above and the country is Canada. Since I can??t view the content of the links provided directly, I need to rely on the image attached to this question for context. Based on that, Option E (the image attached) represents a table with columns ??age?? and ??country??, showing records where age is 75 or above and country is Canada. References: The answer can be inferred from understanding SQL queries and their outputs as per Databricks documentation: Databricks SQL
