- (Exam Topic 5)
You have an Azure Synapse Analytics dedicated SQL pool.
You runPDW_SHOWSPACEUSED('dbo.FactInternetSales');and get the results shown in the following table.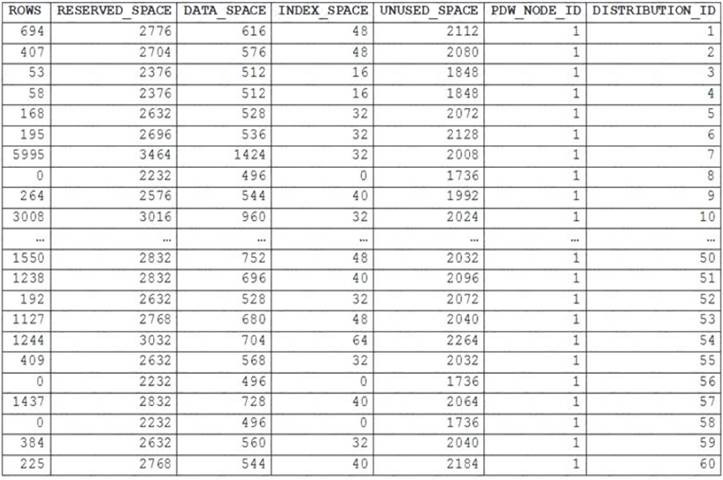
Which statement accurately describes thedbo.FactInternetSalestable?
Correct Answer:
D
The rows per distribution can vary up to 10% without a noticeable impact on performance. Here the distribution varies more than 10%. It is skewed.
Note: SHOWSPACEUSED displays the number of rows, disk space reserved, and disk space used for a specific table, or for all tables in a Azure Synapse Analytics or Parallel Data Warehouse database.
This is a very quick and simple way to see the number of table rows that are stored in each of the 60 distributions of your database. Remember that for the most balanced performance, the rows in your distributed table should be spread evenly across all the distributions.
ROUND_ROBIN distributed tables should not be skewed. Data is distributed evenly across the nodes by design.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribu https://github.com/rgl/azure-content/blob/master/articles/sql-data-warehouse/sql-data-warehouse-manage-distrib
- (Exam Topic 5)
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes mapping data flow, and then inserts the data into the data warehouse.
Does this meet the goal?
Correct Answer:
B
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity, not a mapping flow,5 with your own data processing logic and use the activity in the pipeline. You can create a custom activity to run R scripts on your HDInsight cluster with R installed. Reference:
https://docs.microsoft.com/en-US/azure/data-factory/transform-data
- (Exam Topic 3)
Which counter should you monitor for real-time processing to meet the technical requirements?
Correct Answer:
B
Scenario: Real-time processing must be monitored to ensure that workloads are sized properly based on actual usage patterns.
To monitor the performance of a database in Azure SQL Database and Azure SQL Managed Instance, start by monitoring the CPU and IO resources used by your workload relative to the level of database performance you chose in selecting a particular service tier and performance level.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/monitor-tune-overview
- (Exam Topic 5)
You are creating a new notebook in Azure Databricks that will support R as the primary language but will also support Scala and SQL.
Which switch should you use to switch between languages?
Correct Answer:
B
You can override the default language by specifying the language magic command %
Reference:
https://docs.microsoft.com/en-us/azure/databricks/notebooks/notebooks-use
- (Exam Topic 2)
What should you implement to meet the disaster recovery requirements for the PaaS solution?
Correct Answer:
B
Scenario: In the event of an Azure regional outage, ensure that the customers can access the PaaS solution with minimal downtime. The solution must provide automatic failover.
The auto-failover groups feature allows you to manage the replication and failover of a group of databases on a server or all databases in a managed instance to another region. It is a declarative abstraction on top of the existing active geo-replication feature, designed to simplify deployment and management of geo-replicated databases at scale. You can initiate failover manually or you can delegate it to the Azure service based on a user-defined policy.
The latter option allows you to automatically recover multiple related databases in a secondary region after a catastrophic failure or other unplanned event that results in full or partial loss of the SQL Database or SQL Managed Instance availability in the primary region.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/auto-failover-group-overview
